近期在处理个耗时高的优化建议时,发现Dictionary的setter非常耗时,记录过程如下
- 环境 Xcode 10.1 Swift 4.2
今天对一个粗暴的递归排序算法做优化:
func sortForNear(points: [JSON]) {
var s = Coord(lat: latitude, lng: longitude)
while arr.count > 0 {
arr.sort { (a1, a2) -> Bool in
let dis1 = s.getDisance(ot: a1)
let dis2 = s.getDisance(ot: a2)
return dis1 < dis2
}
s = arr[0]
arr.remove(at: 0)
}
}
(注:此次用索引id给数组的每个项做了唯一值标识)
第一次优化,把每次计算过的值用字典做缓存,期望减少重复计算来减少耗时
private var dict: [Int : [Int : CGFloat]]!
private func getDis(_ a: Coord2D, _ b: Coord2D) -> CGFloat {
guard let dis = dict[a.id]?[b.id] else {
let dis = a.getDisance(b)
if dict[a.id] == nil {
dict[a.id] = [Int : CGFloat]()
}
dict[a.id]?[b.id] = dis
return dis
}
return dis
}
func sortForNear() {
dict = [Int : [Int : CGFloat]]()
while arr.count > 0 {
arr.sort { (a1, a2) -> Bool in
let dis1 = (s.id < a1.id) ? getDis(s, a1) : getDis(a1, s)
let dis2 = (s.id < a2.id) ? getDis(s, a2) : getDis(a2, s)
return dis1 < dis2
}
s = arr[0]
arr.remove(at: 0)
}
}
改写后重新测试,耗时仍旧非常久,某些情况下居然比没优化前还要耗时。
如以800个子项为例,用时18s左右
后经过性能分析,发现是字典的set非常耗时,累计set了32w+次,是总耗时中的大头
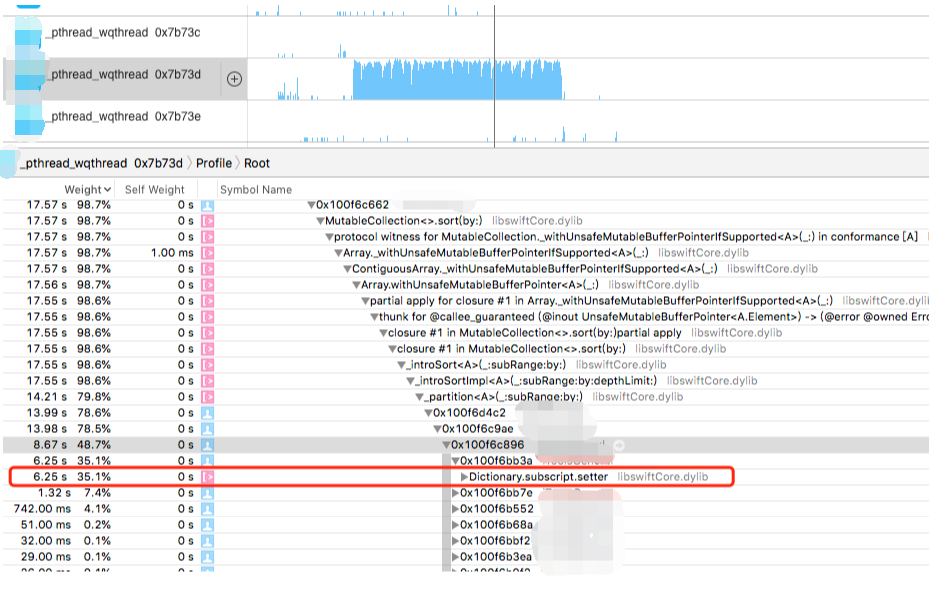

遂考虑改用二维数组来缓存值,同样的例子,耗时不到5s,近4倍的性能提升
private var disArr: [[CGFloat]]!
private func getDis(_ a: Coord2D, _ b: Coord2D) -> CGFloat {
var dis = disArr[a.id][b.id]
if dis < 0 {
dis = a.getDisance(b)
disArr[a.id][b.id] = dis
}
return dis
}
func sortForNear() {
disArr = [[CGFloat]](repeating: [CGFloat](repeating: -1.0, count: max), count: max)
while arr.count > 0 {
arr.sort { (a1, a2) -> Bool in
let dis1 = (s.id < a1.id) ? getDis(s, a1) : getDis(a1, s)
let dis2 = (s.id < a2.id) ? getDis(s, a2) : getDis(a2, s)
return dis1 < dis2
}
s = arr[0]
arr.remove(at: 0)
}
}
原理:
经过对字典的实现原理的分析,可能出现差异的原因在于setter的操作实现上
Swift中字典采用了线性探测的开放寻址法,在set时需要做哈希值冲突的处理,查找插入的位置
而上面用到的二维数组,在初始化时已分配好位置,同时用唯一的索引值确定了插入的位置,几乎没有查找的过程
总结:
原先下意识的以为是getDisance多次调用导致的耗时,后来减少了调用,也没发现总耗时减少了,经过排查才知道方向错了。。